

 Processing
Processing
xGen™ NGS Amplicon Sequencing
Our amplicon solutions enable you to advance from sample to sequencing faster, without sacrificing coverage or yields. If your research requires rapid, ready-to-sequence materials or you are working with low-input quantities, xGen NGS can unlock the answers you seek.
xGen NGS—made to amplify.
Overview
What is amplicon sequencing?
Amplicon sequencing is an experimental method of targeted next generation sequencing (NGS) that enables you to research the sequence of specific genomic regions. This method uses PCR to create copies of your targeted DNA sequences to create amplicons. Unlike a typical PCR experiment with a single set of forward and reverse primers, amplicon sequencing panels include multiple sets of primer pairs to copy multiple regions of the DNA simultaneously. Individual research samples used for amplicon sequencing must be transformed into libraries by adding adapters and enriching target regions to each of the amplicons with a second PCR amplification or adapter ligation. The adapters allow the amplicons to adhere to the flow cell or bead for NGS sequencing. The amplicons from different research samples can be pooled (referred to as multiplexing) which involves adding a barcode or index sequence to the samples so they can be identified during data analysis. The adapters can either include the index sequences or can be added during the PCR amplification step. Depending upon the number of amplicons in the targeted sequencing library, one lane of the sequencing flow cell can decode hundreds to thousands of indexed libraries.
As seen in Figure 1, xGen NGS Amplicon Sequencing technology uses multiple overlapping amplicons in a single tube, using a rapid, 2-hour workflow to prepare ready-to-sequence libraries for research studies. The PCR1+PCR2 workflow generates robust libraries even from low input quantities of DNA that may be subsequently quantified and normalized with conventional methods such as Qubit® (Thermo Fisher Scientific) or Agilent Bioanalyzer® or normalized using the included xGen Normalase™ reagents.
Key benefits include:
- Amplify hundreds to thousands of targets in a single tube PCR
- Amenable for low input samples such as cell-free DNA (cfDNA)
- Supports high throughput methods
- Can be designed for a variety of research applications including variant detection or targeted pathogen sequencing
- Compatible with Illumina® sequencing platforms with the correct adapter and index sequences
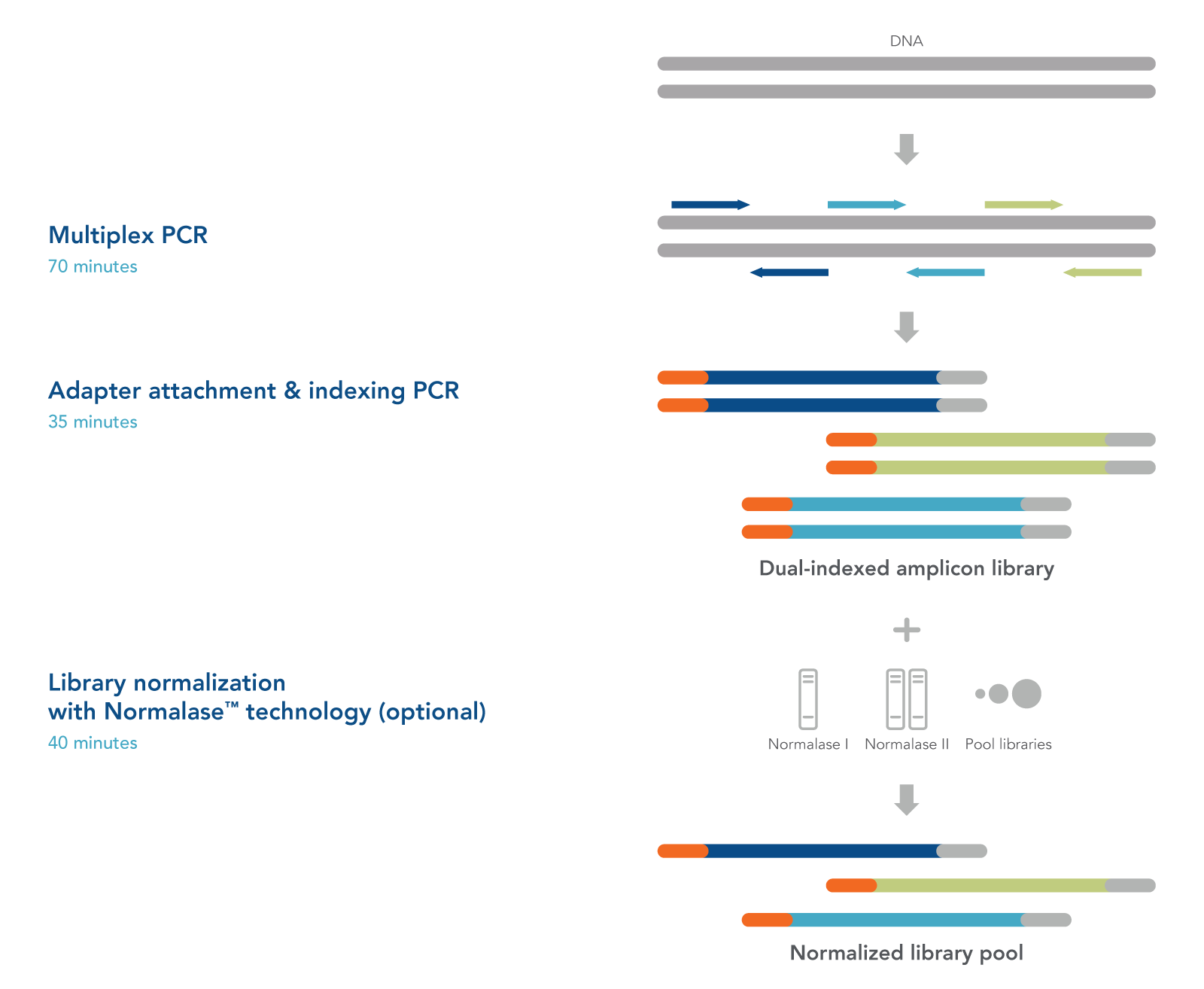
Figure 1. xGen Custom Amplicon Panels have a single tube workflow that is done in as little as 2 hours. Creating an NGS library starts with multiplex PCR. Your custom panel is combined with the DNA sample to amplify the targets of interest. The samples are then amplified with indexing primers to create a functional dual indexed library. As an optional step, the xGen Normalase reagent can be used after pooling multiple libraries to ensure each is equally represented in the final sample for the flowcell.
Ordering
Confused by the options available for our amplicon sequencing products? Not sure what you need in addition to the panel? Investigate the options and suggestions using our xGen NGS Solutions Builder Tool.
xGen NGS Solutions Builder Tool
Let us help make selecting the right solutions easy!
Explore NGS optionsRUO21-0280_001.1